





In a world where data pours in from every direction, researchers are always looking for small, clever ideas that preserve meaning without carrying the full weight of a crowd. A new piece of work from the Indian Institute of Technology Kharagpur in India, led by Bubai Manna, dives into a problem with a deceptively simple name and a surprising amount of punch: the Minimum Selective Subset, MSS for short. At first glance it feels like a puzzle from a math club, but its implications ripple through how we think about data reduction, pattern recognition, and the hard math behind keeping color labels honest as you trim away the noise.
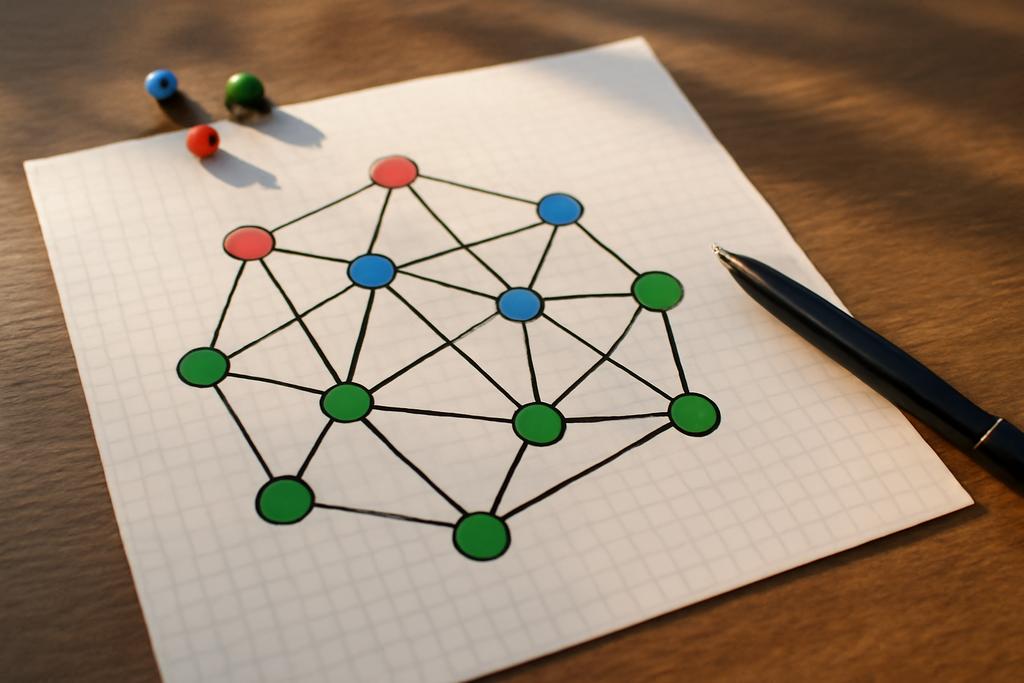
To understand MSS, picture a network of points, each colored by a label. The goal is not to pick a giant representative set, but to pick as few vertices as possible so that every vertex has a nearby neighbor of the same color among the chosen ones or among the rest of the graph. The catch is that the neighbor must be the closest one in its color, and the subset we choose has to be as tiny as possible. The authors frame this in the language of graphs, where colored blocks—groups of adjacent vertices sharing the same color—play a central role. The project is anchored in theory, but the motivation feels practical: if you can distill a complex labeled network down to a compact, color-faithful core, you can speed up learning, reduce storage, and still trust the structure the colors imply.
It’s worth naming the context: MSS is the little brother of a better-known problem called Minimum Consistent Subset. In the late 1990s and beyond, researchers studied related questions about choosing a small training subset that preserves nearest-neighbor consistency. MSS had remained the more enigmatic cousin—proven hard in general, but not as well explored across structured graph families. Bubai Manna’s team at IIT Kharagpur tackles that gap head-on, delivering a map of when the problem is stubbornly hard and where it suddenly becomes tractable. The result is not a single algorithm that solves every instance, but a landscape where we understand the terrain: general graphs resist compact solutions, some structured graphs yield elegant speed, and a few geometric- or tree-like worlds make MSS hum in linear time.
What MSS is really about and why it matters
Meanings in graphs often arrive through the way colors partition the vertices. In MSS, the requirement is precise: for every vertex v that wears color ℓ, there must be a nearest neighbor to v, either among the chosen set S or among the vertices outside its color class, that shares color ℓ. And among all possible selective subsets that satisfy this rule, S must be as small as possible. The constraint sounds delicate, almost musical: you want every color to be locally represented, but you don’t want to oversample the graph just to achieve it.
The paper makes a crucial distinction that helps illuminate the challenge. A related notion, the Minimum Consistent Subset, asks for a subset that preserves color-consistent nearest neighbors for every point, but MSS relaxes a part of that requirement by allowing the rest of the graph to absorb some of the color dynamics. This subtle shift changes the math in meaningful ways. On the one hand, it preserves the intuition that you want a compact set of anchors in the graph. On the other hand, it introduces a family of structural questions: how do you ensure everyone finds a same-colored neighbor with the fewest anchors, and what happens when the graph’s geometry becomes more or less friendly to color matching?
The authors do not shy away from the big-picture implications. In supervised learning and pattern recognition, data summarization is a daily concern: how can you keep the essential decision boundaries intact while discarding superfluous points? MSS gives a formal lens for thinking about that, especially in settings where color labels capture important classes. If you imagine a social network where colors denote communities or tastes, MSS asks for a smallest possible set of representatives that preserves the local idea of “same-color neighbors.” It’s a principle that echoes in active learning, sketching, and even some privacy-conscious data reduction schemes where you want to minimize exposure while keeping structure intact. The IIT Kharagpur team anchors the discussion in rigorous graph theory, even as the ideas ladder toward practical relevance.
A practical ceiling: an O(log n) approximation for MSS in general graphs
One of the paper’s first big moves is to show that, in general graphs with any number of colors, MSS admits an O(log n)-approximation, where n is the number of vertices. That’s not a miracle cure, but it’s a meaningful ceiling. The result rests on a clean, natural bridge: the authors reduce MSS to the classic Set Cover problem. They do this by peeling the graph into blocks—maximal connected subgraphs of vertices sharing a color—and then building a universe of elements and a collection of subsets that capture which vertices can cover which nearby color-neighbors. The key observation is that the blocks are effectively independent in terms of how they must be covered. Once you recast MSS as a Set Cover instance, the greedy algorithm—familiar to anyone who’s brushed up on approximation algorithms—delivers the same logarithmic guarantee you’d expect for Set Cover.
Concretely, the authors define a multi-layered structure: blocks Bi,1 and Bi,2 that collect vertices adjacent to different colors, and a consolidated Ball set that folds in second-order proximity. Each potential selective vertex yields a subset of the universe, and a cover of these subsets translates back into a selective subset of the graph. The upshot is elegant: the MSS problem inherits the well-known greedily achieved approximation bound from Set Cover. The mathematics is not glamorous in a fireworks sense, but it’s precise and powerful. The practical takeaway is that, for large, messy graphs where an exact MSS is out of reach, you still have a principled, scalable method to obtain a reasonably small selective subset with provable guarantees.
The work emphasizes an important theme in algorithmic graph theory: when you cannot solve a problem exactly, find a faithful surrogate that preserves the essential structure. Here, the reduction to Set Cover serves as that surrogate. It also signals a natural boundary: for the broad universe of general graphs, you should not expect to bypass the combinatorial complexity entirely. The O(log n) result gives researchers and practitioners a robust baseline. It tells you how far MSS can be from the optimal in the wilds of big graphs, while also highlighting the structural features you might exploit in practice—like clustering, locality, or color-block separations—that could improve performance in real-world data.
Planar graphs: hardness even on the friendliest ground
Planar graphs—the kind you might imagine when cities are laid out on a map or when circuit boards are designed—often offer a glimmer of tractability for otherwise hard problems. In this paper, planarity does not save MSS. The authors prove that MSS remains NP-complete even when restricted to planar graphs with just two colors. That is a stark reminder that adding geometry or face-to-face structure doesn’t automatically rescue a combinatorial problem from the clutches of intractability.
The route to this conclusion is a careful, geometric reduction from Planar Rectilinear Monotone 3-SAT, a constraint-satisfaction problem known to be hard even under tight planarity and structure restrictions. The construction introduces variable gadgets and clause gadgets laid out on the plane, mirroring the logic of a SAT instance. The gadgets are connected in a way that preserves planarity while encoding the yes/no structure of the underlying formula. The punchline is precise: a satisfying assignment corresponds to a selective subset of a particular size, and conversely, any selective subset of that size yields a satisfying assignment. In short, planarity does not lighten the MSS load; it simply relocates the challenge into a carefully choreographed geometric layout.
Why does this matter beyond a theoretical boundary? First, it frames the computational landscape. If MSS were easy on planar graphs, we might hope for efficient algorithms that leverage planarity to prune the search space. The result tells us to look elsewhere for those shortcuts. Second, it sharpens our intuition about where we might expect practical heuristics or fixed-parameter strategies to shine. If planarity isn’t enough, perhaps other structural parameters—like treewidth, degree bounds, or color distribution patterns—could be the right lever. The paper’s result thus helps researchers calibrate their expectations and directs attention to the most promising structural avenues for future breakthroughs.
Where MSS shines: linear-time triumphs on trees and unit interval graphs
If MSS is tough in general, the authors uncover two gleaming pockets where things snap into place: trees and unit interval graphs. In both cases, the problem becomes tractable in linear time for any number of colors. That’s not a fluke; it’s a demonstration that the right structure turns a hard global problem into a friendly local one you can solve edge to edge, leaf to leaf.
On trees, the approach hinges on the intuitive idea that a block of same-colored vertices can be handled largely independently from other blocks. The authors break each tree into color-homogeneous subtrees and then solve each block with a bottom-up dynamic programming flavor. A careful two-phase process builds small atomic choices—the MB sets within blocks—while maintaining global consistency. The analysis shows that this local decomposition respects the MSS constraints and, crucially, that the total time scales linearly with the number of vertices. It’s a clean example of how a global constraint order can be satisfied by disciplined local reasoning, provided you respect the graph’s hierarchical structure.
Unit interval graphs—think of a tidy lineup of equal-length intervals on a line—offer a second, geometry-friendly victory. Here the authors exploit the left-to-right order inherent in the representation. They still organize vertices into B1 and Ball-like structures, but the sweep across the axis becomes the engine of the algorithm. The rightmost and leftmost adjacent relationships do the heavy lifting, and the algorithm mirrors the tree’s spirit: process in a linear pass, make local decisions that preserve the global selectivity condition, and guarantee optimality within each connected unit-interval subgraph. The upshot is robust: MSS can be solved in linear time on both trees and unit interval graphs, regardless of how many colors appear in the graph.
What makes these results especially compelling is the combination of theory and potential practice. Trees and unit interval graphs aren’t just abstract curiosities; they model real-world structures in scheduling, biology, and hierarchical networks. The ability to compute MSS optimally in these settings unlocks the possibility of using selective subsets as principled, minimal sketches of large labeled systems. If your data naturally sits on a tree-like structure or arranges itself in a unit-interval fashion, you now have an exact, scalable tool for getting a compact, color-faithful summary of the graph’s local structure.
The implications, the limits, and where the field could go next
This paper does more than chart a few isolated results. It sketches a map of where MSS is tractable, where it stubbornly resists, and where practical approximations can bridge the gap. The immediate implication for researchers is a clear call to examine other structured graph classes—perhaps chordal graphs, interval graphs with relaxed constraints, or graphs of bounded treewidth—to see whether MSS admits similarly elegant, linear-time algorithms. It also nudges the community to refine parameterized approaches: could MSS be fixed-parameter tractable when the number of colors is small, or when the desired subset is small in a way that aligns with real-world data sparsity?
For practitioners, the results illuminate the trade-off between exactness and efficiency. If your application can tolerate approximate solutions, the general O(log n) technique provides a reliable baseline. If your data manifests as a tree or a unit interval graph, you can obtain exact, linear-time MSS solutions, which could translate into faster training data selection, smarter summarization, or more compact representations in pattern recognition pipelines. The contrast between what’s hard in the plane and what’s easy on a tree or a line graph also gives a practical intuition about how to structure data pipelines: if you can structure or approximate your data to fit into a tractable class, you gain a predictable computational advantage without sacrificing the integrity of color-based relationships.
Beyond the immediate results, Bubai Manna’s work underscores a more human takeaway. In a world that often celebrates raw scale, there is real value in cutting through complexity with careful structure. The MSS problem—rooted in nearest-neighbor ideas and color partitioning—forces us to confront the tension between brevity and fidelity. The study shows that by listening to the graph’s blocks, its trees, and its orderly intervals, we can keep the essential color story intact even as we trim away the extraneous. It’s a reminder that in data and in life, sometimes the most honest summaries emerge not from brute force but from a disciplined, almost architectural, view of the structure we’re trying to preserve.
The research is a testament to the vibrant curiosity of academic work at IIT Kharagpur and to the modern habit of cross-pollinating ideas from theory to potential practice. It invites a broader audience to appreciate how abstract questions about colors and nearest neighbors can illuminate practical questions about data reduction and learning. As the field continues to push MSS into new corners—new graph classes, new approximations, new practical demands—the work already done will serve as a sturdy compass for what’s possible and what remains waiting to be discovered.



