





In the glow of the operating room, a hyperspectral camera peers at tissue in wavelengths our eyes cannot see. It paints a spectral map that can separate tumor from healthy brain, or distinguish a blood vessel from surrounding tissue with a precision that feels almost cinematic. But turning that map into a reliable guide requires teaching machines to label every pixel, and that task is daunting. In surgical settings, labelling every possible class is expensive, time-consuming, and sometimes impractical. Researchers have long known that simply penalizing all mistakes the same way makes learning slower and less faithful to real-world meaning. The image becomes a blur of plausible but not truly useful distinctions.
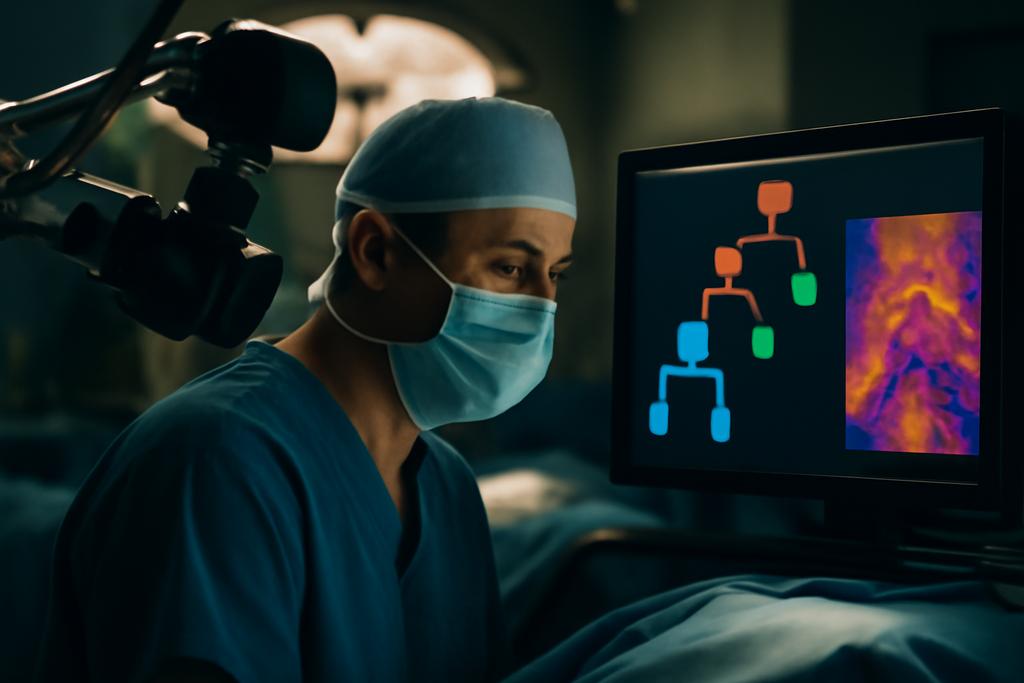
A team at King’s College London, led by Junwen Wang and Tom Vercauteren, offers a different philosophy. They treat the label space as a family tree, a structured map that encodes how classes relate to one another. Rather than treating mislabeling as a generic error, their approach rewards semantic sensibility: confusing a leaf class with its close relatives is less damaging than mixing two far-apart categories with no shared lineage. This is not just clever math; it’s injecting clinician wisdom directly into the learning objective. The work centers on sparsely annotated, multi-class hyperspectral data gathered in the surgical theater, where labels are precious and every extra bit of information counts. The result is a pair of tree-aware losses that push the model to respect the hierarchy of tissue types, and a demonstration that such losses can beat traditional cross-entropy even when labels are scarce.
Crucially, the study also shows how this semantic scaffolding enables safer, more reliable operation in the wild. By weaving the structure of clinical labels into the objective, the model learns a more coherent map of tissue types. And because the approach integrates with an existing framework for sparse, background-free annotations, it can be applied without requiring the onerous pixel-perfect labelling that medical datasets often demand. In other words, the tree becomes a guide rope through a fog of uncertain data, helping the AI keep its footing when the ground truth is sparse or ambiguous.
To foreground the human side of the story, the authors emphasize a real, practical constraint: intraoperative imaging must be fast, accurate, and interpretable. The dataset behind the study—nearly 23,000 labelled frames drawn from dozens of neurosurgical cases—was annotated by neurosurgeons and then carefully propagated across frames to build a robust, hierarchical ground truth. The work is anchored at King’s College London and King’s College Hospital, and the authors openly connect their methods to the needs of surgeons who rely on real-time tissue differentiation to guide delicate maneuvers. The project embodies a collaboration between clinicians, imaging scientists, and machine-learning researchers, and it foregrounds the idea that domain knowledge can dramatically amplify what sparse data can teach a model.
What the paper did
At the heart of the work are two novel losses that encode the label tree into the training objective. The first, a tree-based semantic cross-entropy loss (which the authors call Ltce), broadens the traditional cross-entropy by aggregating probabilities not only over the leaf labels, but over every node in the hierarchy. In practical terms, instead of punishing a mislabel as if it were a completely unrelated category, the loss accounts for how semantically close the predicted node is to the true node. If the model confuses a normal brain region with another nearby normal region, the penalty is smaller than if it mistakes healthy tissue for a malignant lesion deep in a different part of the tree. The depth of the tree and the weights on its edges encode clinical intuition about how dangerous or clinically meaningful certain errors are.
Second, the authors introduce a Wasserstein-distance-based loss defined on the same label tree. Wasserstein distance, a concept borrowed from optimal transport, measures how much “work” it would take to morph one probability distribution into another, with the ground distance defined by the tree. When you couple this with the hierarchical structure, the model learns to move probability mass in ways that respect semantic closeness. In short, predictions drift along the branches of the tree rather than jumping across distant branches in a single step. The authors explicitly show that when the ground distance mirrors the hierarchy, the loss respects the idea that some confusions are more forgivable than others.
These two losses are not just alternative metrics; they are semantically informed objectives designed to work with sparse, background-free annotations. The researchers combine them with an approach that had already shown promise for sparse labelling in medical imaging, enabling pixel-level segmentation even when only a subset of pixels is labelled as a positive class. The result is a learning signal that leverages structure in the label space to guide the model when data is scarce, and to do so in a way that aligns with clinical reasoning.
The data backbone of the study is a richly structured 107-class label tree derived from neurosurgical contexts, organized into four top-level categories: surgical equipment, abnormal tissue, normal tissue, and vascular structures. The leaf nodes (the 107 subclasses) sit at the bottom of this tree, but the model also learns from probabilities assigned to higher nodes. The hierarchy was curated by domain experts and designed to mirror how surgeons think about tissue types and their clinical relevance. The paper also explores how different ways of weighing the tree levels affect performance, revealing that top-level edges tend to have outsized influence when evaluating at the corresponding level, while more nuanced gains appear when considering leaf-level accuracy with the right edge weights.
On the experimental front, the authors report cross-validation results that show clear improvements of the tree-based losses over strong baselines that rely on leaf-only cross-entropy or standard Wasserstein losses without semantics. They quantify performance with metrics that matter in practice, such as true positive rate, balanced accuracy, and F1 score, and they show that semantically aware losses yield more meaningful confusion patterns—particularly a cleaner distinction between normal and abnormal tissue—than a plain cross-entropy loss. They also extend the framework to out-of-distribution (OOD) segmentation, building on a prior approach to detect OOD pixels even when only positive foreground classes are annotated. This combination of hierarchical learning and safe, explicit OOD handling is a notable stride toward trustworthy intraoperative AI.
The project’s experimental backbone includes a thoughtful exploration of how to set the ground distances M on the tree. They investigate several configurations, including top-level weighting, leaf-weighted schemes, and hybrids that distribute weights across levels. Their results show that the right semantic weighting matters: it can push the model toward better performance at both the high level (e.g., simply distinguishing broad classes like normal vs abnormal tissue) and the leaf level (the fine-grained classes surgeons might care about). A key takeaway is that the hierarchy itself is valuable, but how you encode its trustworthiness into the loss shapes how strongly the model respects that trust during learning.
Why it matters in the operating room
The leap from clever losses to real surgical impact is nontrivial, but the paper makes a convincing case that hierarchy-aware learning can be a practical advantage when annotations are sparse. In the operating room, every pixel matters—yet collecting exhaustive, pixel-perfect labels across more than a hundred tissue types would stall progress for years. The tree-based losses let researchers extract more signal from fewer labels by telling the model not just what a pixel is, but where that pixel sits in a semantic neighborhood of tissues. This is especially valuable for distinguishing tumor margins, edema, necrotic tissue, or vascular structures—areas where a clinician experiences subtle, context-rich cues that a patient-specific model should learn to respect.
The study’s results also speak to a broader problem in medicine: safety under uncertainty. By using a framework that explicitly encodes which mistakes are more severe, the model’s failures align more closely with clinical risk. If the model confuses two nearby normal tissues, that’s a different kind of error than mistaking tumor tissue for healthy cortex. The hierarchical losses encode exactly that distinction in the learning objective, nudging the AI toward predictions that are clinically plausible even when the data is imperfect or atypical.
Another practical boon is the integration with OOD detection at the pixel level. In real surgeries, the scene changes fast, and organs or pathologies can present in ways that the model never saw during training. The capacity to flag uncertain regions—without sacrificing performance on known, in-distribution tissue types—gives surgeons a safety net. It’s the difference between a system that confidently labels only what it knows and one that says, in effect, “I’m not sure about that spot, so treat it as a risk zone.” That kind of transparency matters when lives are on the line.
From a product and workflow perspective, the work is anchored in a practical stack: a U-Net with an EfficientNet-B5 encoder, trained with the sparse-plus-tree losses on the 107-class hierarchy. The authors emphasize that all the heavy lifting—data augmentation, training schedules, and the sparse annotation pipeline—was designed with realism in mind: this is not a lab demo but a path to real intraoperative use. The careful balance of performance and practicality is part of what makes the study compelling: it’s not just theoretical elegance, but a blueprint for deployment in the cockpit of real-time surgery.
Beyond the operating room: future implications
If you squint at the broader AI landscape, the idea of a label tree as a learning guide is surprisingly universal. Many domains grapple with hierarchical or semantic label spaces: from pathology where cell types nest within tissue categories, to satellite imagery where land cover sits in a taxonomy of natural and man-made features, to consumer image datasets that organize objects by coarse-to-fine granularity. The paper’s core insight—let the structure of the label space sculpt the learning signal—could be a blueprint for many domains hobbling along with sparse labels.
There’s also a philosophical thread worth pausing on. In a field too often fixated on raw accuracy, this work puts a lens on what kinds of mistakes matter. It treats domain knowledge not as a static input to pre-stringent labels but as an active, trainable prior embedded in the objective. That shift—learning with a learned sense of hierarchy—feels like a maturation of AI in medicine: not just smarter, but wiser about what counts as a good guess in a life-critical setting.
Of course, no method is a panacea. The hierarchy itself must be crafted with care, which means clinicians and data scientists working together to reflect real diagnostic pathways. The edge-weight configurations used in the study illuminate a practical friction: the choice of how to weight different levels can tilt the model toward certain kinds of errors or confidences. In other words, the power of the approach rests not only on the mathematics but on the quality of the domain taxonomy and the alignment between taxonomy and clinical goals. There are also computational considerations: while not prohibitive, the tree-aware losses add complexity to training and to the interpretation of the model’s outputs, especially when you scale to even larger label trees or multimodal data streams.
Still, the paper’s headline claim is striking: integrating a clinician-curated semantic tree into the loss function can deliver state-of-the-art results for sparsely annotated, multi-class hyperspectral segmentation, and it can do so without compromising the model’s ability to detect out-of-distribution tissue. That combination—performance with sparse labels and safer uncertainty handling—addresses two of the most stubborn pain points in medical AI today. It’s a reminder that the best innovations often come from weaving domain knowledge into the fabric of learning itself, rather than treating data as a pure, context-free playground for algorithmic tinkering.
With ongoing support from institutions like NIHR and Wellcome/EPSRC, and with industry partners who see surgical imaging as a frontier for safer, smarter care, the path from hyperspectral research to operating-room reality is gaining traction. The authors disclose ties to Hypervision Surgical, reflecting the inevitable cross-pollination between academic insight and clinical tooling in this arena. That transparency matters: it frames the work as part of a larger ecosystem where research advances are rapidly translated into tools that surgeons can rely on at the bedside. The study’s authors—at King’s College London and King’s College Hospital—are clear that the goal is not to replace human judgment but to amplify it with structured, semantically aware learning that respects the nuance of real tissue biology.
In the end, the work offers a vivid metaphor for the future of medical AI: a sturdy family tree that helps a machine understand not just who its neighbors are, but how closely they belong to the same family. In a field that often treats labels as flat, interchangeable tags, this tree-based approach invites AI to walk with us along the branches toward better diagnosis, safer surgeries, and more trustworthy decisions when the stakes are highest.



